Aside from the current hype cycle of large language models, there are many AI applications on the verge of clinical utility which could change healthcare workflows. However, most of these models have large neural networks as the backbone of their architecture, which are notorious for being inscrutable: it is not generally known why a model makes the classifications it does. Here I’ll delve into a high level overview of explainable AI (XAI), why it’s needed and what it might look like.
The need for XAI in medicine
The developers of AlphaFold recently won the Nobel Prize in chemistry for ‘computational protein design’: arguably (easily in my opinion) the best deep learning application to the biosciences yet. The algorithm allows users to predict the complex folding of proteins given an amino acid sequence. But as pointed out by people such as Janet Thornton (director of the European Bioinformatics Institute) AlphaFold does not ‘solve’ the protein folding problem. Although it allows us to predict protein folding much more accurately, it does not (yet) give us any insight into why any given sequence folds in the way it does. An explanation is missing.
This is important for medical applications. The imperatives of informed consent and patient autonomy require that clinicians are able to explain their decision making to patients. ‘Because an AI said so…’ is unlikely to satisfy patients, and certainly not recent AI regulation. The EU AI act was ratified early 2024, and while we still don’t know the full implications of this for European researchers and clinicians, we do know that diagnostic implementations will be held to the very highest level of scrutiny. And it is likely not only relevant to European efforts; the Brussels effect means that this legislation will find its way into considerations around the world.
Looking inside boxes
Models can be described as black-box, grey-box, or white-box, referring to the degree to which they intrinsically make sense to us. A white-box model is easily interpretable, perhaps after a little training. For instance, the coefficients of logistic regression being interpreted by clinicians in terms of the odds ratios of disease states. Black-box models, such as deep learning architectures, are opaque to such simple interpretations, even if they are more accurate. This includes most of the ‘AI’ models making headlines today. Grey-box models are somewhere in between. An example may be a pharmacokinetic model which uses known biological processes (e.g. absorption, distribution, metabolism, excretion) and then use statistical methods to make patient-specific predictions. These distinctions aren’t as clear as I’ve made out, but it provides a framework.
Received wisdom describes an accuracy, interpretability trade-off: more accurate models are less interpretable and vice versa. Though some challenge this narrative, it is intuitive and at least has some theoretical grounding (that’s a debate which needs its own exploration).
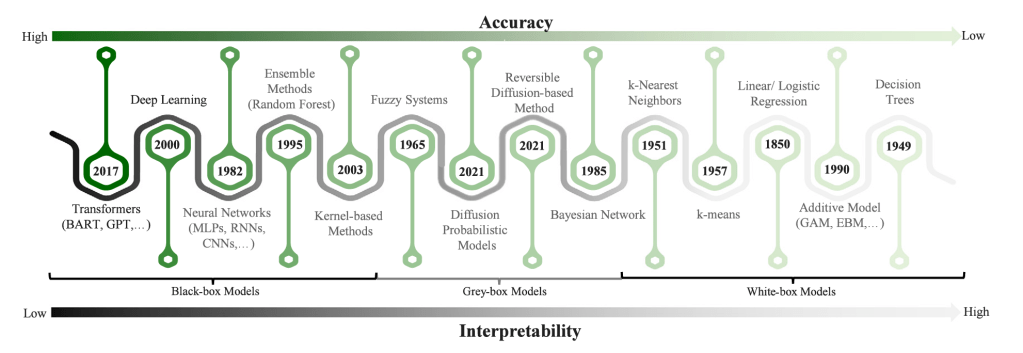
Image taken from Ali et al. (2023), probably the best review on XAI out there right now: https://www.sciencedirect.com/science/article/pii/S1566253523001148
Interpretability and Explainability
We should look into some definitions for interpretability and explainability as they are often conflated, and are used in different ways in different domains interested in XAI. I like to think of interpretability as referring to any model that lends itself to being understood intrinsically and explainability as an additional method or technique applied after the model has been trained to gain some insight.
A good way of think about it (which I got from this review article on XAI) is that explanations can occur at any of three points: the data, the model and a post-hoc explanation of a particular instance.
The first of these is familiar to most people as it’s the bread and better of any analysis, looking at anything from means and correlations to clusterings and dimensionality reduction. It makes sense to understand the data itself, especially given that machine learning is a data dependant process.
The second seeks to understand the model itself, perhaps by approximating the model with another model which is easier to understand, or by describing what various parts of a network might be doing. A nice recent example of this comes from mechanistic interpretability. This involves applying techniques analogous to those used in neuroscience (the brain being the ultimate black-box) to examine ‘neural pathways’, ‘lesion studies and ‘weight modification’. A great example of the latter is the Golden Gate neuron in the Claude 3 LLM by Anthropic: by clamping a specific neuron to ten times its normal value, the team were able to induce it to talk about nothing but the Golden Gate bridge.
Finally, post-hoc explainability usually answers why a specific input (e.g. an image) produces a specific output (e.g. a classification). As such, it cares less about the model itself, seeking only to make a causal inference from input to output. There are a number of ways of achieving this, such as grad-CAM if you have access to the model, or SHAP or ReX if you don’t. As such, the black-box remains untouched but we get to peek inside just a little.
These broad approaches aren’t mutually exclusive, but are building into an ecosystem of tools and techniques, and the skill will be in using the right tool for whatever the task to hand is.
But what is an explanation?
This is not as simple as a question as it would first appear. Ultimately an explanation needs to in some way show why a model gives it outputs in a way understandable to humans. This means an explanation, whatever form it takes, from a text output to an outline on a medical image needs to satisfy human narratives, which are ultimately qualitative in nature. However, an explanation also needs to accurately reflect what the model is doing, which may be amenable to quantitative measures.
An easy to understand explanation is the saliency map, which is a heatmap superimposed upon the input data, usually an image, which shows which part the model is paying attention to in order to makes its classification.
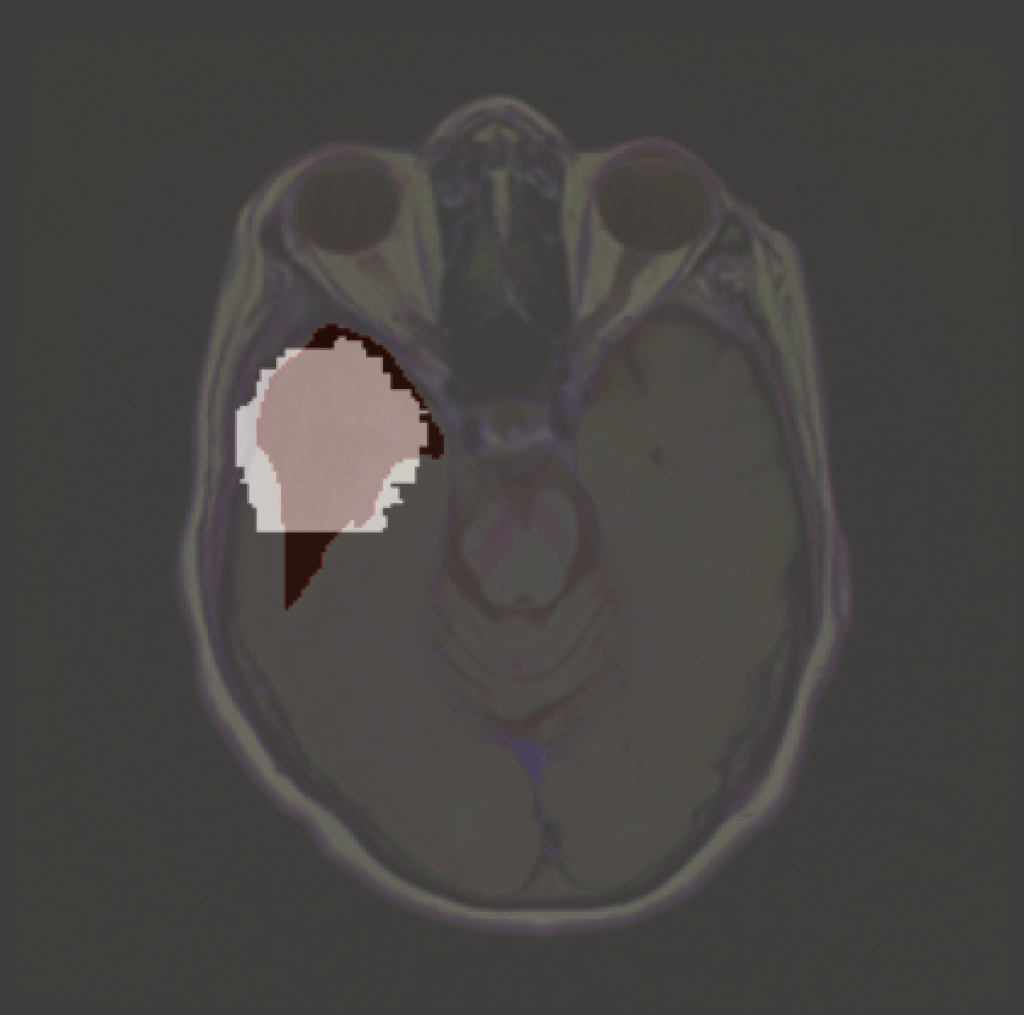
An explanation of an MRI classifier using ReX. Light grey is the explanation, which in ReX corresponds to the approximately minimal set of pixels required by the model to return a positive classification. In dark is a glioma.
There are many XAI tools out there already, all working in slightly, or largely, different ways and providing different insights into what the AI model is doing. We could classify them in terms of what forms their explanations take: visual explanations, textual explanations, concept based explanations or something else completely. The form taken should be the one right for the job: which one that is depends on the use case and, ultimately, the people who will be using it.
This is far from comprehensive, but just illustrates just how vast this domain already is. Unless you are delving into the world XAI I’d recommend not worrying too much about all these and just focus on what you want for a given application – chances are there’s a XAI tool out there there can do the job, or at least serve as a starting point.
I’ve helped out develop and test one such tool, ReX, which I talk about in the below webinar.
Clinical XAI
Despite there being a number of XAI tools, there use in medicine is not established. In part that’s because clinical applications require much higher standards than most regular uses. It’s also because it is not always straightforward to assess how good an explanation actually is.
For these reasons some in the community suggest XAI in medicine is a false dawn, promising something it has yet proven to deliver. There are even suggestions that XAI is not needed at all, that the traditional medical paradigm of evidence based medicine is sufficient for establishing the robustness of AI models. But these are not mutually exclusive, and though XAI may not yet be clinically validated, that doesn’t have to always be the case.
However, it’s certainly true the very few, if any, existing XAI methods have been really scrutinised enough for clinical adoption. That is what I am currently working on. As I see it you need two basic things: the XAI to faithfully say something about the how the model is working. We could call this fidelity. You also need that something to be useful. That could mean being useful to developers, domain users such as clinicians, maybe even legislators. I expect an AI that is good enough to actually be useful in the medical domain it will inevitably retain some level of opacity – and that might be fine to a degree. But it would be useful that we can say somethings about a model, whether that be it internal workings or what features its paying attention to.



Leave a reply to The Future-AI: medical guidelines for AI – Nathan Blake Cancel reply