We frequently hear in the news of the amazing breakthroughs that are happening in the field of AI and medical imaging. The headlines are no less hyperbolic in the medical literature, to the point that a ‘reproducibility crisis‘ is discussed in various papers and editorials in the scientific literature.
I first noticed this problem when I was researching a very narrow domain of medical applications of machine learning: Raman spectroscopy applied to oncological problems. Reviewing the literature I would frequently come across studies boasting accuracies close to, if not exactly, 100%. At the time I couldn’t work out what was wrong, but something didn’t sit right: if these studies really could distinguish between numerous cancers and their various subtypes so accurately, why weren’t they being whisked into the clinical setting to improve cancer diagnostics?

I then came across this paper, which showed that the problem was much broader than the narrow domain I was working in: of 62 studies applying machine learning to diagnose COVID-19 using chest radiographs or CT scans, precisely none were of sufficient quality to be clinically relevant. This despite many of the studies having an accuracy of 100%, or very close. Oh, and these 62 passed an initial quality check, which 258 other papers did not.
The paper goes on to outline a number of short-comings: from the use of low quality public repositories, often including Frankenstein datasets; the lack of external datasets for validation and the improper selection of performance metrics; the unavailability of code so that results could not be reproduced and the need for peer reviewers to be knowledgeable of such concerns. Some of these may concerns are being actively addressed with, for instance, the development of DECIDE-AI guidelines and the BMJ joining a growing list of journals requiring code availability for publication (though whether reviewers will really delve into the code is another question).

One short-coming not explicitly mentioned (though it is certainly implied), is that of data-leakage. This occurs when information from the training set somehow leaks into the test set. In the case of Frankenstein datasets, this can easily occur as researchers may believe all their data is independent and split accordingly, when in reality the same image may exist more than once, one copy going into training and the other into testing. Testing on images that the model has been trained on artificially inflates whatever performance metrics are being used, thus contributing to the generalisation gap.
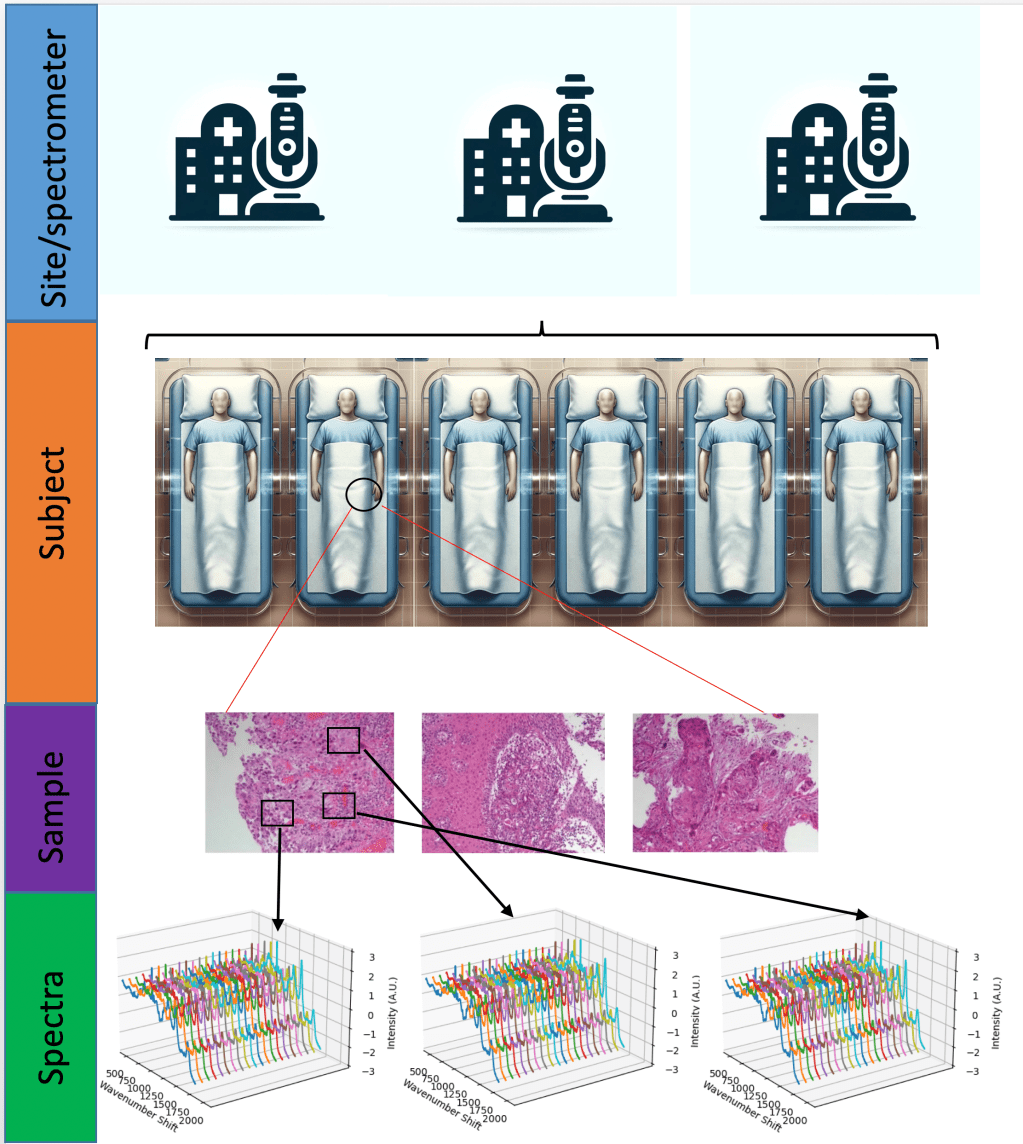
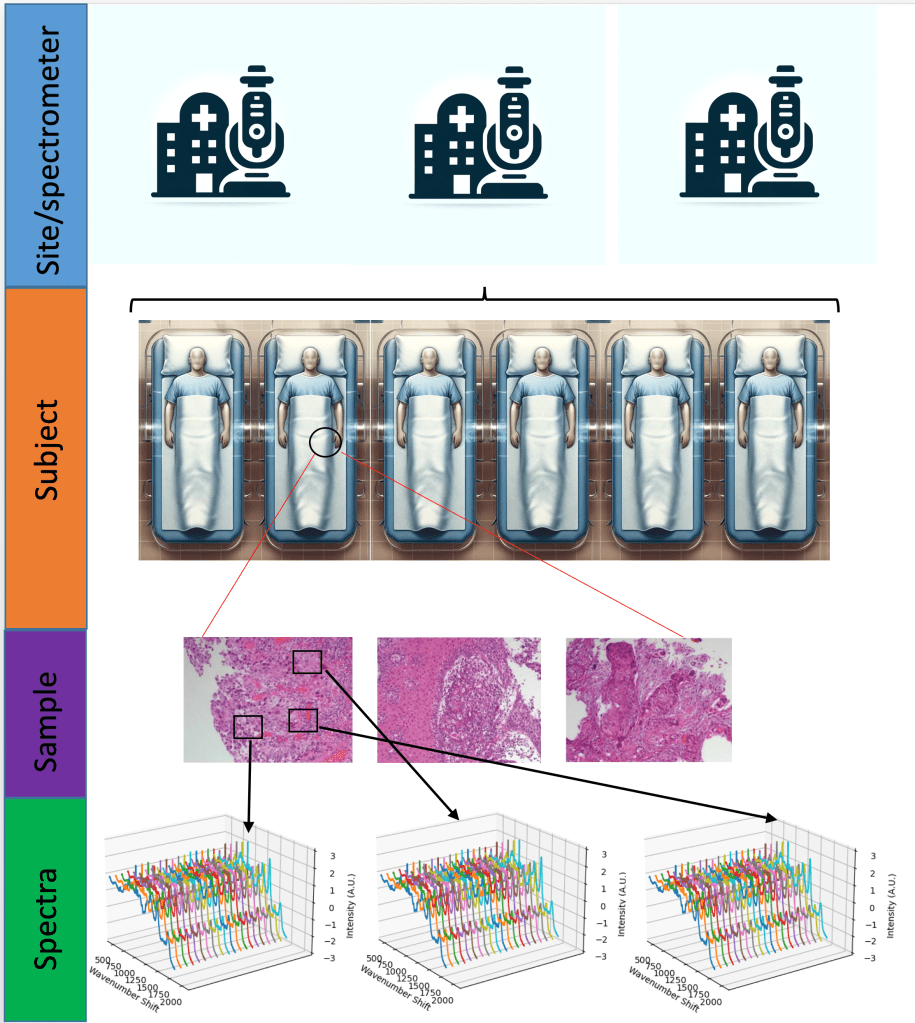
There are many ways in which data leakage can occur. In the case I was looking at, Raman spectroscopy, it snuck in another way. Raman spectroscopy basically uses a particular scattering phenomenon of light, inelastic scattering known as the Raman effect, to build up a ‘picture’ (really a spectrum) of the chemical bonds of something. This could be used on tissue samples to help stage and/or diagnose cancers. And with a plethora of stunning results, you’d think that it was at least close to being deployed in the clinical setting.
However, a great many spectra may be taken from a single sample. Multiple samples are often taken from the same patient, sometimes at the same, sometimes at a different time. This introduces a hierarchical structure to the data. A researcher may split data into training and test sets a the level of spectra, ignoring which samples and which patients they came from. This leads to spectra from the same patient being present in the training and the test set.
Just how much difference does this make? Fortunately we can quantify the effect by performing machine learning on the same dataset, once split at the level of spectra, and again at the level of the patient. Wu et al did exactly that, finding that the latter over-estimated the overall accuracy 12.5%. As I explored in a literature review, this happens more often than not, despite the findings of Wu et al.
This was born out in my own research utilising two different datasets (a two class ovarian dataset and three class colorectal (Lynch) dataset) and three different machine learning models commonly used in Raman spectroscopy.

Such hierarchical structures are very common in medical datasets, and traditional machine learning practitioners, coming from domains with ‘flat’ structures and huge datasets (think cats and dogs), are often unaware of the need to account for this structure. The small sample sizes common to medical datasets further exacerbates this problem, contributing to over-inflation of performance estimates.
All this highlights the need for cross-disciplinary collaboration in computational medicine. As well as the obvious need for computer scientists, who understand the construction of machine learning pipelines, and medical practitioners, who understand the nature of the problems and how data is ultimately generated, there is also a need for statisticians in this domain, who have for decades being analysing datasets with complex dependencies and structures.



Leave a comment